GNU gettext – свободная библиотека проекта GNU для интернационализации, широко применяемая в свободном программном обеспечении.
Основным отличием от других подобных инструментов является то, что в GNU gettext для обозначения переводимых строк в тексте программы используются их английские оригиналы, а не специальные идентификаторы. Таким образом получается, что для отображения интерфейса на английском языке программе не нужны файлы перевода. Это как правило удобно, потому что большинство разрабатываемых приложений и так пишутся на английском.
В GNU gettext есть поддержка множественного числа. Для этого в исходном коде программы используется специальная функция, и приводятся две строки – в единственном и множественном числе. При подстановке перевода на другой язык используется столько форм строки-перевода, сколько нужно для этого языка. Для этого в заголовке файла перевода должно быть специфичное для этого языка выражение для выбора по числу номера строки-перевода.
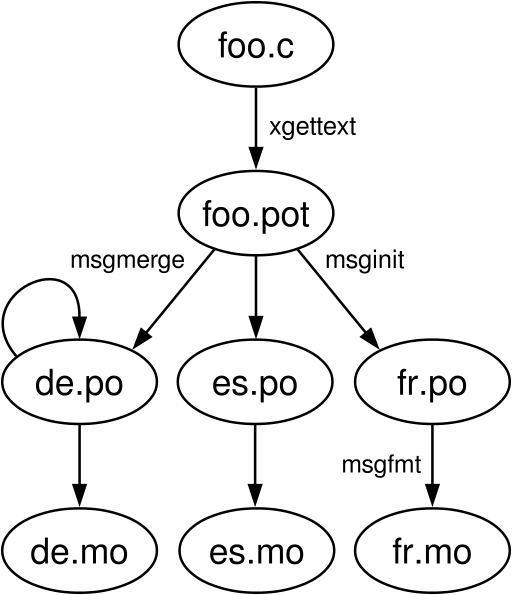
Библиотека GNU gettext предполагает хранение перевода в файлах с расширениями .mo (англ. Machine Object, бинарный файл, удобный для чтения программой и специфичный для платформы), или .gmo (GNU .mo) .po (англ. Portable Object, человеко-читаемый файл перевода, не зависящий от платформы) и .pot (англ. PO template – каталог, заготовка файла .po для перевода на новый язык). Кроме самих строк перевода, .po файлы могут содержать комментарии переводчика и различные служебные пометки.
Для формирования и обновления этих файлов при изменении программы предполагается использование ряда утилит.
Первоначально, строки из исходного текста программы собираются с помощью программы xgettext в .pot-файл (каталог). Обновление этого файла и файлов переводов с использованием новых и изменившихся строк, появившихся в исходном коде, осуществляется программой msgmerge. При этом сохраняются все уже переведённые строки, а те, которые изменились, помечаются как неточные (англ. fuzzy). По умолчанию, такие строки не будут использоваться программой. Они нужны для удобства переводчика: часто проще базироваться на существующем, пусть и устаревшем, переводе, чем переводить всю фразу заново.
Для начала перевода программы на конкретный язык, переводчик создаёт .po-файл: копирует .pot-файл в нужное место и меняет в нём заголовок. Для этого можно использовать программу msginit. Готовый файл перевода конвертируется в .mo-файлы утилитой msgfmt.
Также существуют утилиты для переводчиков, облегчающие редактирование перевода, например:
Кроме базовой реализации GNU gettext для стандартного Си, существуют реализации аналогичного подхода для языков C++, Objective-C, сценарии sh/bash, Python, Perl, PHP, GNU CLISP, Emacs Lisp, librep, GNU Smalltalk, Java, GNU awk, Паскаль, wxWidgets (с использованием класса wxLocale), YCP (язык YaST2), Tcl, Pike и R, языков платформы Mono (пространство имён Mono.UNIX), а так же для фреймворка Qt. Часть этих языков поддерживаются непосредственно упомянутыми выше утилитами.
Использование в большинстве языков схоже с использованием в Си.
Ссылки














